Motivation
At the outset of the DeepAnatomy project, we converged upon the question: what potential do various deep learning based methods have for supporting a qualitative analysis of surgical videos using the example of prostatectomy? In collaboration with the Martini-Klinik in Hamburg, who supplied us with a set of 100 videos of robot-assisted minimally invasive radical prostatectomies, our first goal was to classify frames based on the detection of a single object used during the operation: the specimen bag - a bag used to safely contain the prostate during removal from the patient. Over the course of our project, we built extensions to aid us in video annotation (labeling) and created various pipelines to train a variety of neural networks and perform feature extraction. Among the deep learning methods we tested are: fully connected architectures, convolutional neural networks, transfer learning, recurrent neural networks and transformer models. Centerpiece of our implementation is MeVisLab, a powerful modular framework for image processing that has and continues to be developed by MeVisLab Medical Solutions AG in close cooperation with the Fraunhofer MEVIS research institute and their deep learning framework RedLeaf.
Automatic quality analysis of surgical interventions based on video data is motivated by the need to improve surgical outcomes, enhance patient safety, and advance surgical practices. Manual assessments of surgical quality are subjective and time-consuming, leading to the desire for an objective and standardized approach. By leveraging computer vision and machine learning, algorithms can provide consistent and unbiased evaluations of surgical performance. One key motivation of real time analysis is the early detection of errors and deviations from best practices. Analyzing surgical videos enables algorithms to identify mistakes in instrument handling, tissue manipulation, and adherence to surgical plans. Timely interventions can be implemented, reducing complications and improving overall outcomes. Additionally, automatic quality analysis helps assess surgical technique by evaluating precision, efficiency, and adherence to protocols. Surgeons can receive feedback to enhance their skills and optimize their approaches, leading to better patient outcomes. Furthermore, automatic quality analysis has the potential to revolutionize surgical training and education. Algorithms can analyze a large corpus of surgical videos to extract patterns, identify best practices, and provide valuable guidance to trainees. This standardized approach improves consistency, establishes proficiency benchmarks, and enhances educational programs. Ultimately, it contributes to the development of more competent surgeons and higher standards of care.
Cooperation with Martini-Klinik
The Martini-Klinik is renowned for its expertise in prostatectomy procedures. Our team, known as DeepAnatomy, had the unique opportunity to witness multiple prostatectomy operations at the Martini-Klinik first hand. Our primary objective is to predict the outcome of the operation, thereby increasing the patients chances of healing and reducing incontinence risks. This is achieved through:
- Regular interactions with the surgeons
- Mutual exchange of insights and ideas
Malign prostate cancer is the most frequent form of cancer among men. Radical prostatectomy - the surgical removal of the prostate - is a common procedure performed by medical professionals to remove the tumor before it spreads to the rest of the body. The operation requires a skilled surgeon so that the surrounding nerves and tissue are damaged as little as possible. Damaging the nerve bundles or muscle tissue can cause erectile dysfunction and urinary incontinence, sometimes irreversibly.
In recent years, an increasing share of procedures have utilised robot-assisted laparoscopic surgery (also known as keyhole surgery). This is a minimally invasive approach, where the surgical instruments are inserted into the abdomen via small cuts (as opposed to open surgery, which is done with one big incision). The abdomen is filled with gas to create both space to operate in and pressure that can counteract bleeding during the procedure. Among the instruments inserted is a twin-lens camera that streams the images to the surgeons console. Here, the eyes of the surgeon each view a separate display that receives one of the images, in effect generating true 3D vision. Hand and foot controls are used to steer the individual instruments.
A market leader for surgical robots is the Da Vinci Surgical System by the company Intuitive Surgical. These robots were used in the videos of the radical prostatectomies we received for our deep learning analysis.
Data annotation via extended SATORI Tool
The videos were initially devoid of annotations. Our primary objective was to classify the presence of a specimen bag in each frame. In order to train a model to accurately predict whether a given frame contains a specimen bag or not, annotations were required. We manually annotated the frames containing specimen bags using a tool called Satori, which is a Fraunhofer MEVIS-developed tool specifically designed for annotating medical images. To enhance and expedite this laborious process, we implemented a slice labeling extension for Satori. Utilizing this extension, we are able to annotate frames and indicate the presence or absence of a specimen bag. To expedite the annotation process, we focused on annotating solely the entry and exit points of the specimen bag. By leveraging this information, we were able to classify the frames in between accordingly. Each video underwent manual annotation, and the annotations were thoroughly reviewed by a peer to ensure accuracy and consistency. The annotations created through this process were specifically employed for training and testing a neural network, utilizing deep learning techniques. The neural network was trained using the annotated frames to learn the patterns and characteristics associated with the presence or absence of a specimen bag in the videos. This trained network was then used to classify and predict the presence of specimen bags in unseen frames, thereby aiding in the analysis and understanding of the videos.
At the start of the project the data set contained 14 videos of radical-prostatectomies, provided by the "Martini Clinic". Due to the nature of radical-prostatectomy procedures, video length and operation duration exhibit significant variability. Each operation entails a distinct set of steps, which may require different amounts of time to complete. Consequently, the data set offers videos with varying lengths, capturing the complete surgical journey from start to finish. As is common in deep learning, the data set is partitioned into different groups. Eight videos are allocated for training the model, three videos are reserved for validation purposes, and three additional videos are set aside exclusively for the final testing phase. These test videos have not been exposed to the model during the training process and are specifically used to assess the model's performance. The "Martini Clinic" has contributed an additional set of 86 videos, bringing the total number of videos to 100. These videos were carefully handpicked by medical professionals as they represent intriguing and noteworthy cases. In addition to the surgical footage, each video is accompanied by comprehensive patient information. This includes details on the patient's recovery progress, whether they regained continence, and the duration of their hospital stay.
Methodology
As an initial milestone, our primary objective was to detect a specific object used during a crucial phase of the operation. In this case, our focus was on identifying the specimen bag, which is employed to extract and contain the (partially) removed prostate for further analysis. This task naturally divides the surgical procedure into two distinct parts: the successful removal of the prostate and the subsequent suturing of the bladder. One of the significant challenges we encountered early on was the sheer size of the video files. To overcome this obstacle, we devised a solution to convert the video material into feature vectors. A feature vector is an ordered list of numerical properties of observed phenomena. To accomplish this, we employed the VGG19 deep neural network, renowned for its 19-layer depth, ensuring its capability to extract meaningful features from the videos. Using feature vectors allowed us to classify a whole video, which is typically an hour long, in just a few minutes.
Transfer Learning
The fundamental concept of Transfer Learning is to use the features of a problem that have already been learned and apply them to a similar use case. Transfer learning is a great option, especially for use cases where the data is not sufficient to train an entire model from scratch.In the context of image processing, it means that abstract concepts such as patterns or edges can already be learned and recognized from the pre-trained model. These concepts can then be transferred to the new use case.
Generally, transfer learning includes the following steps: First, a part of a pre-trained model is extracted. This network is also called the backbone. Suitable layers for the use case are then built on top of the backbone, which are called head. The weights of the pre-trained model are frozen, i.e. they are not updated during training. The head can now be trained on the new data set and learn to predict the new use case with the help of the pre-trained network. There are two forms of transfer learning:
Transfer Learning Workflow
- Extract part of pre-trained model (backbone)
- Build layers for the use case on top of the backbone (head)
- Freeze weights of pre-trained model
- Train the head on the new data set

Feature Extraction
In feature extraction, the data is sent through a pre-trained network. As a result, feature vectors are produced. These can then be used to train a smaller network. This is a fast and comparatively cheap option.- Data is sent through a pre-trained network
- Produces a feature vector
- Feature vectors can be used to train a smaller network
- Faster and cheaper to train network on feature vectors
Fine-Tuning
Fine-tuning involves two training stages:In fine-tuning, the network is first trained a few iterations with frozen backbone weights, and only the head is trained on the new data set. Then, all weights are unfrozen, and the entire network is re-trained for the use case using a low learning rate, to minimize the chance of overfitting. Thus, in contrast to pure feature extraction, the backbone is also tuned. However, the system is larger and more complex to train. The advantage over feature extraction, however, is that augmentations can also be applied to the data during training. This could be very important, especially for use cases with small amounts of data.
It is important to train the head first, otherwise the generated features of the pre-trained network could be destroyed by the randomly initialized weights of the untrained head.
- The network is trained for a few iterations with frozen backbone weights so that only the head is trained
- Training the head first is important to avoid destroying generated features of the pre-trained network
- Unfreeze all weights
- Re-train entire network
- Use a low learning rate to minimize the risk of overfitting
- Enables us to apply data augmentation that is crucial when dealing with small data sets
- More complex and time-consuming compared to pure feature extraction
Application of Fine-Tuning and Feature Extraction
In our project, we tested different pre-trained network architectures and decided to use the VGG19 architecture with ImageNet weights for the specimen bag classification use case.This network is specifically designed for object detection and is therefore well suited for our use case. For classification, we have now built a simple head that consists mainly of dense layers and finally makes a binary decision whether there is a specimen bag on the input image. We also performed a feature extraction on the data. This data was then used to train a simple model consisting of dense layers, as well as various sequential models such as RNNs, GRUs, and Transformers.
- VGG19 for object detection as backbone
- Simple head consisting mainly of dense layers for classification
- Binary classification: Specimen bag or not
- Performed feature extraction and trained simple dense layer models and various sequential models (RNNs, GRUs, and Transformers)
- Applied fine-tuning using the VGG19 as backbone and a simple dense layer architecture as head
Results
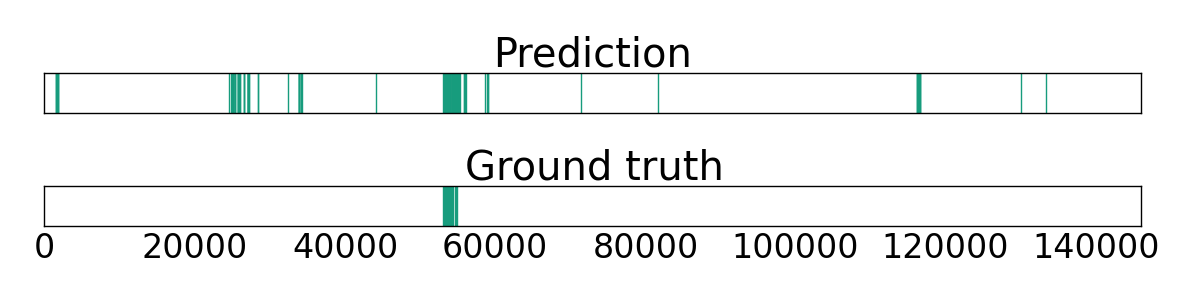
According to the first task, we utilized different architectures of neural networks to perform a per frame classification. More accurately, each frame should be classified as containing the specimen bag or not.
The general training procedure was as following:
- Labels were created using the extended SATORI tool
- Training was performed on feature vectors (Fully connected architecture with feature extraction) or video frames (Fully connected architecture with fine-tuning)
- VGG-19 was selected as the pre-trained architecture (ImageNet weights) for feature extraction
- Data was split into training, validation and test set based on a 8-3-3 split of the videos
- Minimizing the Categorical Cross-Entropy Loss function
Fully connected architecture with feature extraction
As our first approach, a basic fully connected architecture was implemented as follows:- Global max pooling to squeeze spatial dimensions of feature vectors
- One fully connected layer with 128 units and ReLU activation
- Output layer with 2 units and softmax activation
As our first task has a rather simple character, we assumed this small architecture as sufficient to tackle the problem. And indeed, further increasing the number of layers or units did not improve the result, but rather led to overfitting issues. The best model achieved a balanced accuracy of 78% on the test set. The results of the Feature Vector Model can be seen in the table below.
Fully connected architecture with fine-tuning
In this approach, we first trained a network consisting of a VGG19 backbone and a head with fully-connected layers, similar to the previously described architecture.Only the weights of the head were updated. Next, we re-trained the entire network using the same and also a smaller learning rate. In both trainings could be observed that overfitting occurred after a certain number of iterations. We used the best iteration of the first and second training, and we achieved a balanced accuracy of 92% for the specimen bag classification on the test data set.
- First, only weights of head were updated during the training
- Second, the entire network was re-trained using the same and a smaller learning rate
| Model | Balanced Accuracy (%) | Sensitivity (%) | Specificity (%) | Precision (%) | F-Score (%) |
|---|---|---|---|---|---|
| Fine-Tuning model I | 91 | 93 | 90 | 10 | 17 |
| Fine-Tuning model II | 83 | 69 | 98 | 26 | 37 |
| Feature Vector model | 78 | 79 | 100 | 77 | 62 |
Sequential models
For follow-up tasks, a fully connected architecture might not be sufficient anymore. This lead us to utilize more complex and powerful types of neural networks. Although the aforementioned fully connected architecture performed well for our task, we continued to try and find room for improvement with more sophisticated models. In the context of video data, it makes sense to take advantage of the temporal dimension; or, in our case: the classification of the current feature vector (representing one frame) can be improved by integrating information extracted from previous feature vectors (frames). Sequential models seemed a natural choice and we carried out experiments utilizing different types of Recurrent Neuronal Networks (RNN's) and a Transformer architecture. All models were trained on sequences generated like the following:- Every 5th frame of the video is selected
- Sequence lengths of 50-200 frames (depending on configuration)
- Each sequence represents 2-8 seconds in the video
Recurrent neuronal networks process sequential data step-by-step and unfold their potential by accumulating the extracted information from each step in a kind of internal memory, the hidden state. At each step a feature vector of the extracted sequence gets processed as follows:
- The feature vector gets fed into the RNN cell
- The cell processes the current input while integrating the information of the hidden state of the previous time step
- The RNN cell produces an output for the time step
- The hidden state is passed onto the next time step
In our scenario at each step a feature vector from the extracted sequence is fed into the network, gets processed while integrating the information of the hidden state and produces an output, representing the classification of the current feature vector. Afterwards, the hidden state is passed onto the next step and the process is continued until the end of the sequence.
Different RNN-based architectures were tested, designed by using the following guidelines:
- 1-2 recurrent layers followed by an output layer with softmax activation
- Cross Entropy Loss function
- Different loss weighting strategies
- Basic RNN, more sophisticated sub-types as the Long Short-Term Memory (LSTM) or Gated Recurrent Unit (GRU)
In general, the use of LSTM- or GRU-based architectures outperform the standard RNN architecture, especially with longer sequences, as they tackle the vanishing gradient problem.
Another alternative architecture that has been tested is the Transformer architecture for classification. This type of model is different from RNNs since it does not rely on recurrent structures, but instead uses an attention mechanism. They were originally used for natural language processing (NLP), but can also be applied to sequence processing.
So far, no good performance could be achieved using the recurrent models or transformer models for our first task, which might arise from the small size of the first data set. Further investigation and experiments are needed.